前編はこちら
§8 発話文脈・変項割当#
という文を発話したとする.この文は,代名詞との2つの指示対象が発話の状況から明らかなときにのみ適切である.このように,文脈に依存して意味が初めて定まる言語表現を直示(deixis)という.指示対象を明らかにするため,次のように代名詞に指標(index)を振ることにする.
とにとという異なる指標が割り当てられているのは,それらが相異なる外延をもつことを表している.
既に述べたように,この文の外延はおよびの指示対象が文脈から定まることで初めて計算することができる.このような文は自由変項*1を含んだ開いた項(open term)として見做すことができる.このような発話に際しての状況をutterance contextと呼ぶ.定訳があるかはわからないので,この記事中では発話文脈と訳すことにする.
発話文脈を形式的に扱う道具立てとして,変項割当(variable assignment)を導入する.Heim and Kratzerでは,変項割当を以下のように定義している*2.
(変項)割当とは,(自然数の集合)からへの部分関数である.
例えば,以下のはいずれもにおける変項割当である.
直示を含む項の意味計算をするには,指示対象を発話文脈に問い合わせる必要があるため,ある変項割当のもとで項の意味計算を行なう必要がある.そこで,変項割当のもとでの項の外延をと表記することにする.以降はの略記であるとする*3.
また,変項(variable)という概念は形式的には次のように定義される*4*5.
終端記号は,となるような変項割当およびが存在するとき,かつそのときに限り変項であるという.
変項は自由変項(free variable)と束縛変項(bound variable)に分類される*6が,ある項が自由変項を含む開いた項であるか,それとも自由変項を含まない閉じた項(closed term)であるかを区別することは重要である.閉じた項の意味計算はその項の内部だけで完結する一方,開いた項の意味計算を行うためには,変項の指示対象を外部から与える必要があるからである.
§8のまとめ#
- 発話文脈に依存して意味が初めて定まる言語表現を直示という
- 発話文脈を形式的に扱うために変項割当という概念を導入する
- これは(自然数の集合)から(個体の集合)への部分関数である
- 直示を含む文の意味計算は変項割当をともなって行なう
§9 新しい言語#
さて,変項割当をHaskell上で表現してみよう.変項割当は自然数の集合から個体の集合への部分関数だったが,項レヴェルの計算で部分関数を扱いたくないので,型レヴェルで扱うことにする.型レヴェルで扱うことにより,適切でない文脈で発話がなされたことを型エラーとして検知することができる.
変項割当を導入したモチベーションは,発話文脈を形式的に扱うことであった.文脈上に存在する値を参照するような計算は,HaskellではReaderとして知られている.ただし,今我々が欲しいのは単なるReaderではなく,型レヴェル自然数を指定した際,その自然数に対応するような値を取ってくることのできるReaderである.このような挙動を実現するため,membershipおよびextensible-skeletonpackageを用い,extensible effectsを用いて対象言語を構築することにする.
自然数と個体の対応関係を表す型index |-> entityを以下のように定義する.ここでindexは型レヴェル自然数である,すなわちNat種をもつ.
import GHC.Types (Type)
import GHC.TypeNats (Nat)
import Data.Extensible.Effects (ReaderEff)
import Type.Membership (type (>:), Assoc, Lookup)
type (|->) :: Nat -> Type -> Assoc Nat (Type -> Type)
type index |-> entity = index >: ReaderEff entity
例えば1 |-> PEANUTSという型は,指標1にPEANUTS型の値が割り当てられていることを意味する.
前編で定義したModel言語を書き換え,extensible effectsに埋め込むことにする.この言語では,項がEff ctx aという型で表現される.ただし,Eff型はextensible-skeletonpackageで定義されている.ここでctxはctx :: [Assoc Nat (Type -> Type)]という種をもち,具体的にはctx = '[1 |-> PEANUTS, 2 |-> PEANUTS]のような型になる.e :: Eff ctx aは直観的には「ctxという文脈を伴ったa型の項e」と読むことができる.
さて,前編で導入したFAとPMという2つの意味計算規則を,この新しい言語に沿う形で再び埋め込む必要がある.
FAはHaskellにおける通常の関数適用として埋め込まれる.前編と同様にis_aという関数を定義しておく.
is_a :: a -> (a -> b) -> b
is_a x f = f x
また,PMは以下のように再定義される.
import Data.Extensible.Effect (Eff)
predicateModification
:: (a -> Eff ctx Bool) -- ^ λx. p(x)
-> (a -> Eff ctx Bool) -- ^ λx. q(x)
-> (a -> Eff ctx Bool) -- ^ λx. p(x) ∧ q(x)
predicateModification p q = \x -> do
p' <- p x
q' <- q x
pure $ p' && q'
また,前編で定義したやといった語彙は以下のように再定義される.
boy :: PEANUTS -> Eff ctx Bool
boy x = pure $ case x of
Charlie -> True
Linus -> True
Schroeder -> True
_ -> False
love :: PEANUTS -> Eff ctx (PEANUTS -> Eff ctx Bool)
love object = do
pure $ \subject -> pure $ case (subject, object) of
(Lucy , Schroeder) -> True
(Sally, Linus ) -> True
(Patty, Charlie ) -> True
_ -> False
例として,の意味計算は以下のように行われる.ただしcuteおよびdogは前編で定義したものを適切に再定義したものとする.
sentence :: Eff '[] Bool
sentence = Snoopy `is_a` cuteDog
where
cute, dog, cuteDog :: PEANUTS -> Eff ctx Bool
cute = _
dog = _
cuteDog = predicateModification cute dog
main :: IO ()
main = hspec $ do
describe "Snoopy is a cute dog" $ do
it "is false" $ do
let denotation = leaveEff sentence
denotation `shouldBe` False
ここでleaveEff :: Eff '[] a -> aという関数が登場しているが,これは文脈が空(すなわちctx = '[])であるような場合にのみ,effectfulな計算から中身を取り出すことのできる関数である.
§9のまとめ#
- 変項割当を型安全に扱うために,以降は
Eff ctx aという言語を用いる- これは発話文脈
ctxを伴ったa型と読める
- これは発話文脈
§10 Traces & Pronouns (T&P)#
下準備が随分長くなってしまったが,いよいよという直示表現を含んだ文の意味計算を行うために,第3の意味計算規則であるTraces & Pronouns (T&P)を導入する*7.
が代名詞または痕跡で,が変項割当であり,がの定義域に含まれるとき,である.
はそれ単体では意味が定まらないが,変項割当によって指示対象が指定されているときに,を用いて意味計算を行なうことができる,ということを表している.ここでは例として
なる変項割当のもとでの意味計算を行ってみよう.
さて,このT&PはHaskellでは以下のように実装できる.ただし前述の通り,変項割当は値レヴェルではなく型レヴェルで表現する.
import Data.Kind (Type)
import Type.Membership (Assoc)
traceOrPronoun
:: forall (index :: Nat) (entity :: Type) (ctx :: [Assoc Nat (Type -> Type)])
. Lookup ctx index (ReaderEff entity)
=> Eff ctx entity
traceOrPronoun = askEff (Proxy @index)
ここで型変数index :: Natは,代名詞または痕跡に与えられた指標(型レヴェル自然数)である.entity :: Typeはその文において考えているモデルに存在する個体の型を表す型変数であり,具体的にはPEANUTS型などが代入される.ctx :: '[Assoc Nat (Type -> Type)]はこの発話がなされた発話文脈,すなわち変項割当である.また,Lookup ctx index (ReaderEff entity)というconstraintは,この変項割当に対する要請を表している.どのような要請かというと,指標indexに対応する個体が定められていることを要求しているのである.
constraintを無視して=>の後ろだけに注目すればEff ctx entityという単純な型をしており,(ctxというeffectsを伴った)個体の型を表していることが見て取れる.また,実装部分はaskEff Proxyと非常にシンプルで,ReaderEff entityというeffectを発生させているだけであることがわかる.ただしこのeffectは型レヴェル自然数indexに対応付けられている.
traceOrPronoun関数を用いてをHaskellに埋め込むと次のようになる.
import Data.Function ((&))
-- | "She(1) loves him(2)."
sentence :: Eff '[1 |-> PEANUTS, 2 |-> PEANUTS] Bool
sentence = do
she <- traceOrPronoun @1
him <- traceOrPronoun @2
lovesHim <- love him
she & lovesHim
このように組み立てた文の意味計算はrunReaderEff関数および前述のleaveEff関数を用いて行う.
runReaderEff
:: Eff ((index |-> PEANUTS) : ctx) a -- ^ ctxの先頭の@index |-> PEANUTS@というeffectを剥がす
-> PEANUTS -- ^ 代わりに指標indexに対応する個体を外から与える
-> Eff ctx a
実際にHaskell上で意味計算を行う様子を以下に示す.
sentence :: Eff '[1 |-> PEANUTS, 2 |-> PEANUTS] Bool
sentence = do
she1 <- traceOrPronoun @1
him2 <- traceOrPronoun @2
lovesHim2 <- love him2
she1 & lovesHim2
main :: IO ()
main = hspec $ do
describe "She(1) loves him(2)" $ do
it "is true when she(1) refers Lucy and him(2) refers Schroeder" $ do
let eval = leaveEff
. flip (runReaderEff @2) Schroeder
. flip (runReaderEff @1) Lucy
denotation = eval sentence
denotation `shouldBe` True
異なる変項割当のもとで意味計算を行った場合,その計算結果は当然違ったものになる.
it "is false when she(1) refers Lucy and him(2) refers Charlie" $ do
let eval = leaveEff
. flip (runReaderEff @2) Charlie
. flip (runReaderEff @1) Lucy
denotation = eval sentence
denotation `shouldBe` False
仮に不十分な発話文脈のもとで文が発話された場合,すなわちrunReaderEff関数で与えた変項割当が不十分である場合,コンパイルに成功しない.leaveEff :: Eff '[] a -> a関数はctxが空('[])であることを要求するため,引数にeffectが残存している場合には型が合わないためである.このように変項割当を型レヴェルで扱うことにより,発話文脈に対する型安全性を獲得することができる.
§10のまとめ#
- T&Pという意味計算規則が導入された
- が代名詞または痕跡で,が変項割当であり,がの定義域に含まれるとき,である.
- 指標を型レヴェルで扱えば,T&Pは
askEff関数によって表現でき,文脈上の具体的な指示対象はrunReaderEff関数によって与えられる
§11 Predicate Abstraction (PA)#
関係代名詞を含んだ文の意味計算をしたい.以下に関係代名詞を含んだ文の例を挙げる.
ただしは関係代名詞が移動した痕跡(trace)である.これらは指示対象としては同じものを指すので,同じ指標を与えることにする.
また,playerはHaskell上で以下のように定義しておく.
player :: PEANUTS -> Eff ctx Bool
player x = pure $ case x of
Snoopy -> True
Charlie -> True
Lucy -> True
Linus -> True
Patty -> True
Schroeder -> True
_ -> False
さて,この文は次のような統語構造を持っている.
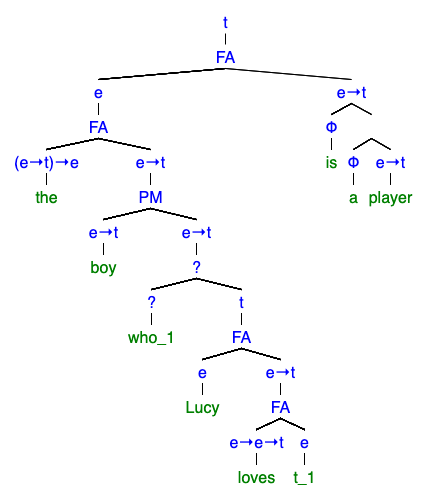
合成性原理(principle of compositionality)を根拠に,この構文木の部分木について考察することは有意義である.そこで,まずこの文の主部であるについて考えてみよう.定冠詞が付いていることから,この名詞節の意味はただ一つに定まる個体であることが予想される.つまり
である.
この個体は発話文脈によらず一定である,すなわちこの名詞句は自由変項を含まない閉じた項になっている.構成要素に変項が含まれていることを考えると,は根に至るまでのどこかで束縛されているはずである.部分木をボトム・アップに観察することによって,その様子を調べてみよう.
#
まずという部分木を取り出すと,この部分の意味は既に知る通りFAとT&Pによって計算することができる.ただし,この項の意味計算には指標の指示対象を定める必要がある.この要請はHaskellの型においてLookup ctx 1 (ReaderEff PEANUTS)という形で現れる.
lucyLovesT1
:: forall ctx
. Lookup ctx 1 (ReaderEff PEANUTS)
=> Eff '[1 |-> PEANUTS] Bool
lucyLovesT1 = do
t1 <- traceOrPronoun @1
lovesT1 <- love t1
Lucy & lovesT1
#
次に,関係代名詞節を見てみよう.この世の中の個体は,Lucyが愛するものとそうでないものに分類することができるので,は個体に関する述語である,つまりは型をもつことが予想される.の目的語である変項に様々な個体を代入してみては,それをLucyが愛してるか否かを検証する,といった具合である.
は純粋に個体に関する述語であり,という項の意味は変項割当に依存しないという点に注目したい.部分木であるは意味計算にあたっての指示対象が定まっている必要があるにも関わらずである.
このような観察から,このが併合されるこの接点において,の部分が抽象化され,なるからへの関数に変換されていることが見て取れる.実際のところ,このような意味計算はどのような規則に基づいて行われると解釈すべきであろうか.『形式意味論入門』4.4.に次のような言明がある.
すると,wh句であるが行っている「仕事」は何だろうか.統語論的には,は姉妹関係にあるタイプの接点をタイプに変換している.語彙的には,本来的にはT&Pによってタイプの個体として外延を導かれるはずの痕跡を,変項に変換している.このふたつの操作を,同時に行うためには,の外延を固定して設定しFAによって併合を行うよりも,新たな意味解釈規則を設定するほうが,汎用性が高い.そこで使われるのがPAという規則である.
つまり,関係代名詞は,「それ独自の外延をもたない」と考える.関係代名詞は,痕跡に割り振られている指標(index)と指示対象を同定する働きをしており,「単なる指標」として存在する.そしての行っている「仕事」は,語彙項目によってではなく,PAによって遂行される.
というわけで,いささか天下り的だが,第4の意味計算規則であるPredicate Abstractionを導入しよう.
Predicate Abstractionは以下のように定義される*8.
が およびを娘に持つ枝分かれ接点で,が代名詞または"such"であるとき,任意の変項割り当てのもとでとなる.
ただしはmodified variable assignmentと呼ばれるもので,以下のように定義される*9.
を変項割当,,とする.このとき,は以下の条件を満たす唯一の変項割当である.
(i)
(ii)
(iii) であるようなすべてのについて
ここで関数に対しはの定義域を表す.
非形式的には,元となる変項割当に対し,を与えたときにを返すように局所的な改変を加えて得られる新たな変項割当がであると言うことができる.
PAを用いての意味計算を行ってみよう.
PAをHaskellで実装すると以下のようになる.
predicateAbstraction
:: forall index entity ctx a
. Eff ((index |-> entity) ': ctx) entity
-> Eff ((index |-> entity) ': ctx) a
-> (entity -> Eff ctx a)
predicateAbstraction _ x = runReaderEff @index x
(index |-> entity) ': ctxという部分に着目してみると,改変前のctxという変項割当に対し,index |-> entityという対応関係をconsして上書きしており,modified variable assignmentを表現している.実装部分は単なるrunReaderEffであり,まさにラムダ抽象を導入するというはたらきをしていることがわかる.
PAを用いたの意味計算をHaskell上で行うと以下のようになる.
-- | 与えられた個体はLucyによって愛されているか?
whoLucyLoves :: Eff ('[] :: [Assoc Nat (Type -> Type)]) (PEANUTS -> Bool)
whoLucyLoves = predicateAbstraction @1 who1 lucyLovesT1
where
who1 :: forall ctx. Lookup ctx 1 (ReaderEff PEANUTS) => Eff ctx PEANUTS
who1 = traceOrPronoun
lucyLovesT1 :: forall ctx. Lookup ctx 1 (ReaderEff PEANUTS) => Eff ctx Bool
lucyLovesT1 = _
effectのlistが空('[])になっており,もはや発話文脈に対して何の制約も課されていないことがわかる.
#
およびについて,どちらも外延は個体に関する述語であるから,この部分木の意味計算はPMによって行う.
-- | 与えられた個体は,少年であり,かつLucyによって愛されているか?
boyWhoLucyLoves :: Eff '[] (PEANUTS -> Bool)
boyWhoLucyLoves = predicateModification boy whoLucyLoves
where
boy, whoLucyLoves :: Eff '[] (PEANUTS -> Bool)
boy = _
whoLucyLoves = _
#
定冠詞の外延はどのようなものだろうか.Heim and Kratzerでは以下のように定義されている*10.
となるようながちょうど1つだけ存在するような任意の関数について,は,を満たすような唯一のである.
与えられた述語を満たすような個体が,考えているモデル内にただ一つだけ存在するとき,その個体をの意味とする.Model PEANUTSにおける語彙の定義に立ち返ると,をにする個体はのみなので,となるはずである.
Haskellでは以下のように実装できる*11.モデル内の個体を列挙する必要があるため,Bounded entityおよびEnum entityという制約を追加せざるを得ない.
the
:: (Bounded entity, Enum entity)
=> (entity -> Eff ctx Bool)
-> Eff ctx entity
the predicate = do
xs <- filterM predicate [minBound..maxBound]
case xs of
[x] -> pure x
_ -> error "multiple entities satisfy the given predicate"
主部の外延がであることがわかったので,あとはFAによってを計算すれば,元の文の外延がであることがわかる.
sentence :: Eff ('[] :: [Assoc Nat (Type -> Type)]) Bool
sentence = do
let boyWhoLucyLoves = predicateModification boy whoLucyLoves
theBoyWhoLucyLoves <- the boyWhoLucyLoves
theBoyWhoLucyLoves & player
where
who1 :: forall ctx. Lookup ctx 1 (ReaderEff PEANUTS) => Eff ctx PEANUTS
who1 = traceOrPronoun @1
lucyLovesT1 :: forall ctx. Lookup ctx 1 (ReaderEff PEANUTS) => Eff ctx Bool
lucyLovesT1 = do
t1 <- traceOrPronoun @1
lovesT1 <- love t1
Lucy & lovesT1
whoLucyLoves :: PEANUTS -> Eff ('[] :: [Assoc Nat (Type -> Type)]) Bool
whoLucyLoves = predicateAbstraction @1 who1 lucyLovesT1
main :: IO ()
main = hspec $ do
describe "The boy who(1) Lucy loves t(1) is a player" $ do
it "is true" $ do
let denotation = leaveEff sentence
denotation `shouldBe` True
§11のまとめ#
- PAという意味計算規則が導入された
- がおよびを娘に持つ枝分かれ接点で,が代名詞または"such"であるとき,任意の変項割り当てのもとでとなる.
- PAは
runReaderEff関数で表現できる
終わりに#
本記事では『形式意味論入門』で紹介されている4つの意味計算規則を,その前提知識を交えて紹介し,Haskellのプログラムに書き下すことで理解を深めた.また,後半の2つの意味計算規則については,Haskell上で型レヴェルの制約を表現することで,発話文脈に関する型安全性を獲得することができた.
本記事では筆者の見切り発車と技術的な制約によりHaskellを採用したが,Haskellでは副作用を扱うにあたってモナドを明示的にユーザに見せるという点であまり良い選択肢ではなかったかもしれない.後編の内容に関して言えば,暗黙にKleisli圏の上で考えるような,algebraic effects and handlersをネイティヴに扱える言語の方が向いているかもしれないので,機会があれば挑戦してみたい.
『形式意味論入門』では専ら外延意味論が取り上げられているが,外延意味論では「はだと考えている」といった形式の,人間の信念に関する文を解釈することが難しい.このような問題に対するアプローチとして,内包意味論という枠組みが知られている.また,モデル論的意味論は,Tarskiによる数学の意味論に端を発するが,これに代わるものとして,証明論的意味論という意味論も展開されている.これはGerhard Gentzen*12やDag Prawitz*13らの数学の意味論を起源とし,PrawitzやMichael Dummett*14による,文の意味を検証条件とする立場を嚆矢とするものである.
「形式意味論の特徴はラムダ演算子である」という触れ込みだったが,実際に意味論の世界で用いられているのは標準的な集合論であり,ラムダ抽象および適用といった記法の使い勝手がよいので広く用いられている,というのが実態であるように感じられた*15.一方で,ラムダ計算の計算的側面に着目し,理論計算機科学の分野で知られている概念を輸入したり,型システムを拡充したりすることによって,有益な示唆が得られたり,実際にモデルの説明力が向上するかもしれない.例としては,量化やフォーカスといったいくつかの言語現象が,継続の概念を用いてうまく説明できることが報告されている*16.他には,依存型を用いると照応がうまく表現できると耳にしたことがある.また,Lambek計算およびコンビネータ論理に立脚した組み合わせ範疇文法(CCG; combinatory categorial grammar)も近年注目を集めているらしく,こちらも今後調べてみたい.
コード全文#
{-# LANGUAGE AllowAmbiguousTypes #-}
{-# LANGUAGE DataKinds #-}
{-# LANGUAGE ExplicitNamespaces #-}
{-# LANGUAGE FlexibleContexts #-}
{-# LANGUAGE KindSignatures #-}
{-# LANGUAGE PackageImports #-}
{-# LANGUAGE PolyKinds #-}
{-# LANGUAGE ScopedTypeVariables #-}
{-# LANGUAGE StandaloneKindSignatures #-}
{-# LANGUAGE TypeApplications #-}
{-# LANGUAGE TypeOperators #-}
module Main where
import "base" Control.Monad (filterM)
import "base" Data.Function ((&))
import "base" Data.Kind (Type)
import "base" Data.Proxy (Proxy (Proxy))
import "base" GHC.TypeNats (Nat)
import "extensible-skeleton" Data.Extensible.Effect (askEff, Eff, leaveEff, ReaderEff, runReaderEff)
import "hspec" Test.Hspec (describe, hspec, it, shouldBe)
import "membership" Type.Membership (type (>:), Assoc, Lookup)
data PEANUTS
= Snoopy
| Woodstock
| Charlie
| Sally
| Lucy
| Linus
| Patty
| Schroeder
deriving (Bounded, Enum)
type (|->) :: Nat -> entity -> Assoc Nat (Type -> Type)
type (index :: Nat) |-> entity = index >: ReaderEff entity
boy :: PEANUTS -> Eff ctx Bool
boy x = pure $ case x of
Charlie -> True
Linus -> True
Schroeder -> True
_ -> False
love :: PEANUTS -> Eff ctx (PEANUTS -> Eff ctx Bool)
love object = do
pure $ \subject -> pure $ case (subject, object) of
(Lucy , Schroeder) -> True
(Sally, Linus ) -> True
(Patty, Charlie ) -> True
_ -> False
cute :: PEANUTS -> Eff ctx Bool
cute x = pure $ case x of
Lucy -> True
Patty -> True
Sally -> True
_ -> False
dog :: PEANUTS -> Eff ctx Bool
dog x = pure $ case x of
Snoopy -> True
_ -> False
player :: PEANUTS -> Eff ctx Bool
player x = pure $ case x of
Snoopy -> True
Charlie -> True
Lucy -> True
Linus -> True
Patty -> True
Schroeder -> True
_ -> False
is_a :: a -> (a -> b) -> b
is_a x f = f x
the
:: (Bounded entity, Enum entity)
=> (entity -> Eff ctx Bool)
-> Eff ctx entity
the predicate = do
xs <- filterM predicate [minBound..maxBound]
case xs of
[x] -> pure x
_ -> error "multiple entities satisfy the given predicate"
predicateModification
:: (a -> Eff ctx Bool)
-> (a -> Eff ctx Bool)
-> (a -> Eff ctx Bool)
predicateModification p q = \x -> do
p' <- p x
q' <- q x
pure $ p' && q'
traceOrPronoun
:: forall (index :: Nat)
. forall (entity :: Type)
. forall (ctx :: [Assoc Nat (Type -> Type)])
. Lookup ctx index (ReaderEff entity)
=> Eff ctx entity
traceOrPronoun = askEff (Proxy @index)
predicateAbstraction
:: forall index entity ctx a
. Eff ((index |-> entity) ': ctx) entity
-> Eff ((index |-> entity) ': ctx) a
-> (entity -> Eff ctx a)
predicateAbstraction _ x = runReaderEff @index x
main :: IO ()
main = hspec $ do
describe "Snoopy is a cute dog" $ do
let cuteDog = predicateModification cute dog
sentence = Snoopy `is_a` cuteDog
it "is true" $ do
let denotation = leaveEff sentence
denotation `shouldBe` False
describe "She(1) loves him(2)" $ do
let sentence :: Eff '[1 |-> PEANUTS, 2 |-> PEANUTS] Bool
sentence = do
she <- traceOrPronoun @1
him <- traceOrPronoun @2
lovesHim <- love him
she & lovesHim
it "is true when she(1) refers Lucy and him(2) refers Schroeder" $ do
let eval = leaveEff
. flip (runReaderEff @2) Schroeder
. flip (runReaderEff @1) Lucy
denotation = eval sentence
denotation `shouldBe` True
it "is false when she(1) refers Lucy and him(2) refers Charlie" $ do
let eval = leaveEff
. flip (runReaderEff @2) Charlie
. flip (runReaderEff @1) Lucy
denotation = eval sentence
denotation `shouldBe` False
describe "The boy who(1) Lucy loves t(1) is a player" $ do
let whoLucyLoves :: PEANUTS -> Eff ('[] :: [Assoc Nat (Type -> Type)]) Bool
whoLucyLoves =
let who1 :: Lookup ctx 1 (ReaderEff PEANUTS) => Eff ctx PEANUTS
who1 = traceOrPronoun @1
lucyLovesT1 :: Lookup ctx 1 (ReaderEff PEANUTS) => Eff ctx Bool
lucyLovesT1 = do
t1 <- traceOrPronoun @1
lovesT1 <- love t1
Lucy & lovesT1
in predicateAbstraction @1 who1 lucyLovesT1
sentence = do
let boyWhoLucyLoves = predicateModification boy whoLucyLoves
theBoyWhoLucyLoves <- the boyWhoLucyLoves
theBoyWhoLucyLoves `is_a` player
it "is true" $ do
let denotation = leaveEff sentence
denotation `shouldBe` True
脚注#
*1: 「自由変項とは何か」をまだ定義していないが,ここではラムダ計算などで現れる一般的な自由変数・束縛変数を想像してもらえば構わない.
*2: Heim and Kratzer §5.3.4
*3: ここで,これまでに導入した意味計算規則に対し,変項割当のもとでの意味計算を行えるような改変を加える必要があるが,自明な改変であるためここでは割愛する.詳しくはHeim and Kratzer §5.2.2を参照のこと.
*4: Heim and Kratzer §5.4.1.ただし原文では変項割当をおよびで表しているが,と少し紛らわしいためおよびを用いた.以下でも断りなく引用中でこのような記法の置き換えを行なうことがある.
*5: 変項でない終端記号を定項(constant) と呼ぶ.
*6: 詳しくはHeim and Kratzer §5.4.1を参照のこと.
*7: Heim and Kratzer §5.3.4
*8: Heim and Kratzer §5.5.ただし,は原文ではという表記になっている.
*9: Heim and Kratzer §5.3.4
*10: Heim and Kratzer §4.4.1
*11: 残念ながら型安全に実装する筋のいい方法を思い付かなかった.意欲のある読者は是非挑戦してほしい.
*12: ドイツの数学者・論理学者.自然演繹やシークエント計算などの功績で知られる.
*13: スウェーデンの哲学者・論理学者.自然演繹における証明の正規化可能性を示した業績などで知られる.
*14: イギリスの哲学者.Fregeの思想の研究や,論理の哲学・数学の哲学・言語哲学に対する貢献で知られる.
*15: Montagueによる原典にあたればまた印象が変わるのかもしれない.